
机器学习数学.md 11 KB
神经网络的基本原理
首先明确,“正向传播”求损失,“反向传播”回传误差。同时,神经网络每层的每个神经元都可以根据误差信号修正每层的权重,
将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程; 由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层; 在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛
为什么需要激活函数
- 首先激活函数是非线性连续的,激活函数有Sigmoid、tanh、Relu、Leaky Relu、Maxout、ELU
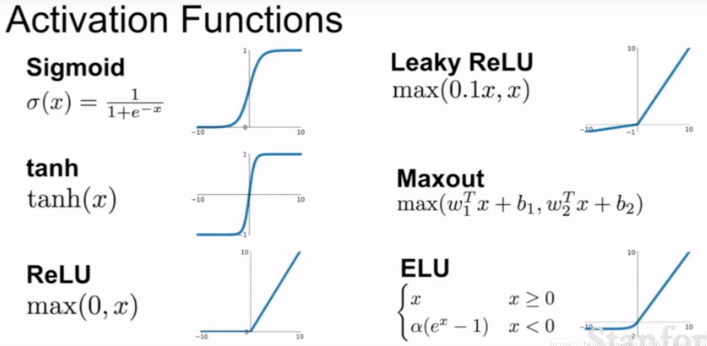
- 激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。
问题一:为什么我们要使用激活函数呢?
如果不使用激活函数,我们的每一层输出只是承接了上一层输入函数的线性变换,无论神经网络有多少层,输出都是输入的线性组合。如果使用的话,激活函数给神经元引入了非线性的因素,使得神经网络可以逼近任何非线性函数,这样神经网络就可以应用到非线性模型中。
问题二:那么为什么我们需要非线性函数?
非线性函数是那些一级以上的函数,而且当绘制非线性函数时它们具有曲率。现在我们需要一个可以学习和表示几乎任何东西的神经网络模型,以及可以将输入映射到输出的任意复杂函数。神经网络被认为是通用函数近似器(Universal Function Approximators)。这意味着他们可以计算和学习任何函数。几乎我们可以想到的任何过程都可以表示为神经网络中的函数计算。
问题三:如何选择激活函数?
1、sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
该函数是将取值为 (−∞,+∞)的数映射到 (0,1) 之间。可以联想到概率,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。sigmoid函数的公式以及图形如下:
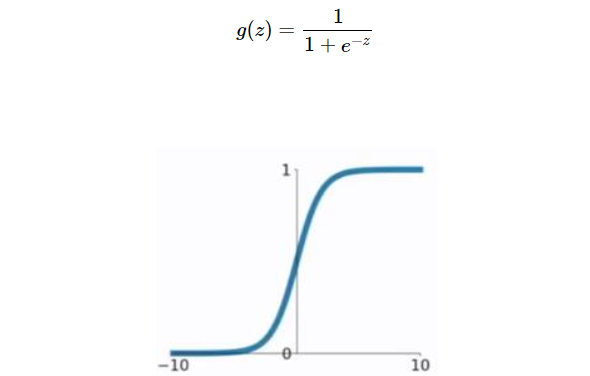 缺点:
缺点:
当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。
函数输出不是以0为中心的,这样会使权重更新效率降低。对于这个缺陷,在斯坦福的课程里面有详细的解释。
sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
2、tanh 激活函数: tanh 是非常优秀的, 几乎适合所有场合。
该函数是将取值为 (−∞,+∞) 的数映射到(−1,1) 之间,其公式与图形为:
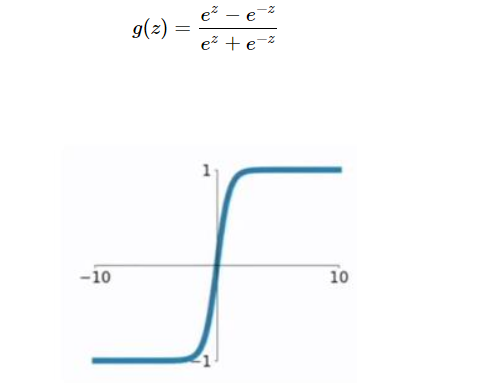 tanh函数的缺点同sigmoid函数的第一个缺点一样,当 z 很大或很小时,g′(z)接近于 0 ,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。因此再介绍一个机器学习里特别受欢迎的激活函数 Relu函数。
tanh函数的缺点同sigmoid函数的第一个缺点一样,当 z 很大或很小时,g′(z)接近于 0 ,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。因此再介绍一个机器学习里特别受欢迎的激活函数 Relu函数。
3、ReLu 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者Leaky ReLu。
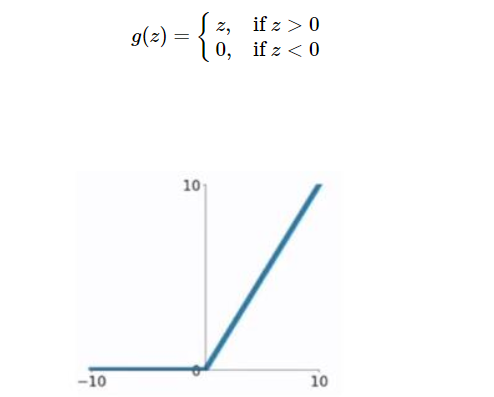 只要z是正值的情况下,导数恒等于 1,当z是负值的时候,导数恒等于 0。z 等于0的时候没有导数,但是我们不需要担心这个点,假设其导数是0或者1即可。
只要z是正值的情况下,导数恒等于 1,当z是负值的时候,导数恒等于 0。z 等于0的时候没有导数,但是我们不需要担心这个点,假设其导数是0或者1即可。
激活函数选择的经验:如果输出是0和1的二分类问题,则输出层选择 sigmoid 函数,其他层选择 Relu 函数
为什么要计算导数,斜率的作用。
- 以二元一次方程为例,斜率可以认为是函数图像倾斜的方向。
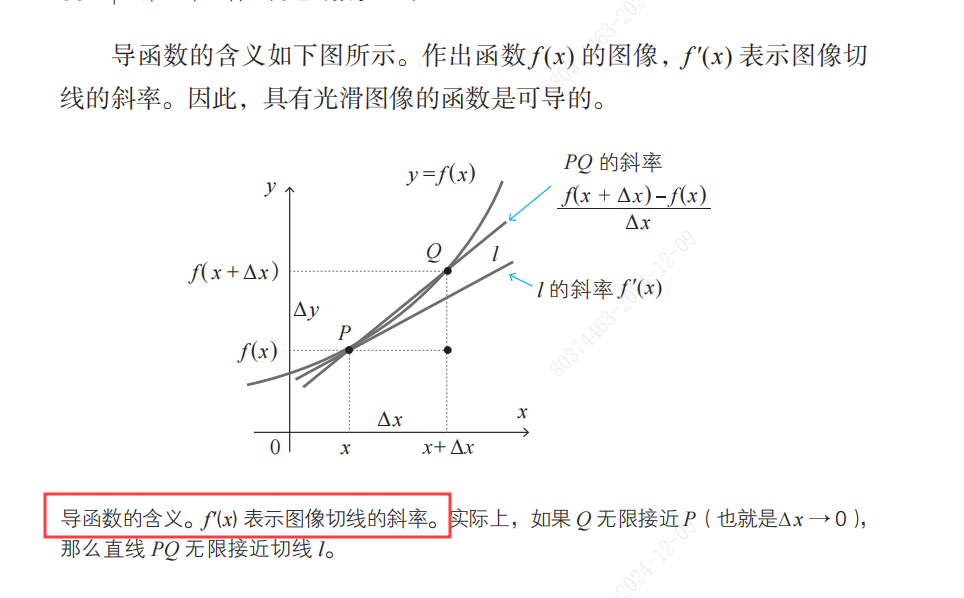
- 最小值条件,当函数f(x)在x = a处取得最小值时,f'(a) = 0。

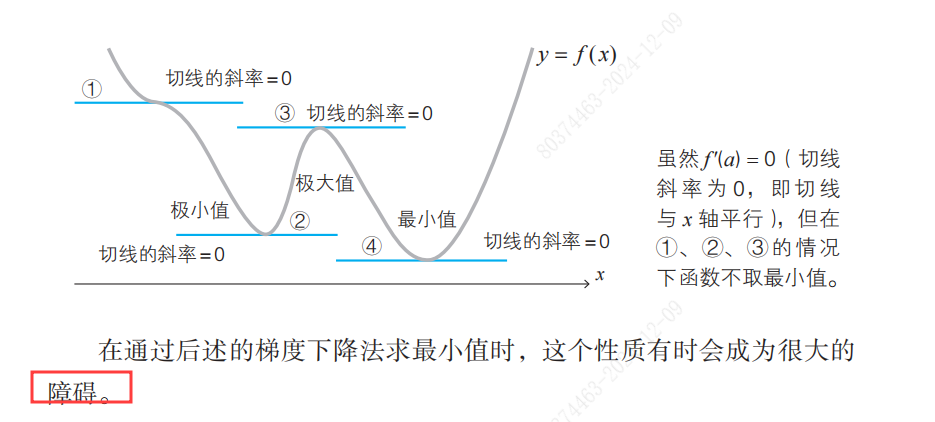
- 神经网络是一个多变量的函数, 所以推导得到每个变量的偏导数为0,为最小值的必要条件
- 可参考二元一次的导数,指向的是当前斜率的方向

神经网络的数学推导对比
误差函数
- https://www.cnblogs.com/hider/p/17095700.html
- 在回归任务中(对连续值的预测),常见的评估指标(metrics)主要包括:
平均绝对误差 MAE(Mean Absolute Error)
均方误差 MSE(Mean Square Error)
均方根误差 RMSE(Root Mean Square Error)
平均绝对百分比误差 MAPE(Mean Absolute Percentage Error)
其中,MAE 和 MSE 使用较为广泛。
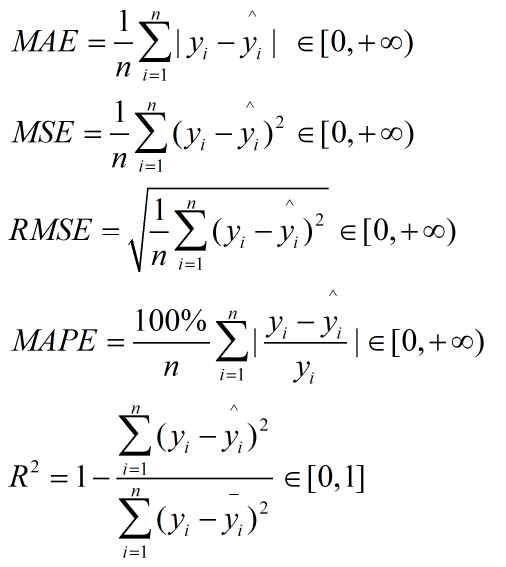
误差反向传播解决的问题
- 反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称。
- 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
- 梯度下降法需要计算损失函数对参数的偏导数,如果用链式法则对每个参数逐一求偏导,这是一个非常艰巨的任务!


- 模型参数非常多,现在的神经网络中经常会有上亿个参数,而这里每求一个分量的偏导都要把所有参数值代入损失函数求两次损失函数值,而且每个分量都要执行这样的计算。
- 复合函数非常复杂
- 学习误差反向传播法有两种方式:一是基于计算式,这种方法严密且简洁,但是对数学功底要求比较高;二是基于计算图
卷积神经网络讲的是什么,为什么要这么设计
卷积神经网络(Convolutional Neural Networks,简称CNNs)属于深度学习(Deep Learning)领域中的一种神经网络架构。它特别适用于处理具有网格状拓扑结构的数据,例如图像(2D网格)和视频(时间序列上的2D网格)。CNNs在以下方面表现出色:
图像识别和分类:
CNNs是图像识别和分类任务中的首选模型,能够识别图像中的模式和特征。 计算机视觉:
除了图像分类,CNNs也被广泛应用于其他计算机视觉任务,如目标检测、语义分割、实例分割、姿态估计等。 视频分析:
在视频领域,CNNs可以用于动作识别、视频分类等任务。 医学图像处理:
CNNs在医学图像分析中用于肿瘤检测、细胞分类等任务。 自然语言处理(NLP):
尽管CNNs主要用于图像处理,但它们也被用于一些NLP任务,如句子分类、文本分类等,尤其是在结合循环神经网络(RNNs)时。 推荐系统:
在推荐系统中,CNNs可以用于处理用户和物品的图像信息,以提高推荐的准确性。 生成模型:
作为生成对抗网络(GANs)的一部分,CNNs可以用于生成图像、艺术作品等。 强化学习:
在强化学习领域,CNNs可以从视觉输入中提取特征,用于训练智能体。 卷积神经网络的核心优势在于其卷积层能够捕捉输入数据的空间层次结构和局部特征,这使得它们非常适合处理图像和视频数据。随着深度学习的发展,CNNs已经成为许多视觉任务的标准解决方案。
线性神经网络一般能处理什么问题?
- 线性神经网络由于其结构简单,主要适用于处理线性可分问题,即那些可以通过线性决策边界清晰区分不同类别的问题。
- 线性回归(Linear Regression):
- 用于预测连续数值的问题,例如房价预测、股票价格预测等。
- 逻辑回归(Logistic Regression):
- 用于二分类问题,即预测两个类别中的一个,例如垃圾邮件检测、疾病诊断等。
- 多类分类(Multi-class Classification):
- 可以扩展到多于两个类别的分类问题,例如手写数字识别、动物种类分类等。
- 线性可分的异常检测(Anomaly Detection):
- 识别数据集中的异常或离群点,例如信用卡欺诈检测。
- 线性可分的聚类问题(Clustering):
- 在特征空间中将数据点分组,使得同一组内的数据点相似度高,不同组之间的相似度低。
线性神经网络中包含的数学:
概率论基础:
作用:概率论提供了理解随机变量、概率分布和统计推断的基础,这对于理解神经网络中的参数初始化、激活函数和损失函数等概念至关重要。
数据科学的几种分布:
作用:了解不同的数据分布(如正态分布、二项分布等)有助于理解数据的特性和模型的假设条件。在神经网络中,激活函数的选择可能与数据分布有关。
熵和激活函数:
作用:熵是衡量数据不确定性的指标,与激活函数的选择有关。在线性神经网络中,激活函数通常是线性的,但在输出层可能使用softmax函数进行多类分类。
回归分析:
作用:线性神经网络可以用于回归问题,其中目标是预测连续值。回归分析提供了评估模型性能的方法,如均方误差(MSE)和平均绝对误差(MAE)。
假设检验:
作用:在线性神经网络的训练过程中,假设检验可以帮助评估模型的有效性和参数的显著性。
相关分析:
作用:相关分析有助于识别特征之间的线性关系,这对于特征选择和理解模型的输入输出关系很重要。
方差分析:
作用:方差分析(ANOVA)可以用来比较不同组之间的均值差异,这在某些分类问题中可能有用。
其他问题:
- 预测能力也称泛化能力或者推广能力,而训练能力也称逼近能力或者学习能力。一般情况下,训练能力差时,预测能力也差,并且一定程度上,随着训练能力地提高,预测能力会得到提高。但这种趋势不是固定的,其有一个极限,当达到此极限时,随着训练能力的提高,预测能力反而会下降,也即出现所谓过拟合现象。出现该现象的原因是网络学习了过多的样本细节导致,学习出的模型已不能反映样本内含的规律,所以如何把握好学习的度,解决网络预测能力和训练能力间矛盾问题也是BP神经网络的重要研究内容。